CREATE INDEX test1_id_index ON test1 (id);
CREATE INDEX test2_info_nulls_low ON test2 (info NULLS FIRST);
CREATE INDEX test3_desc_index ON test3 (id DESC NULLS LAST);
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));
CREATE INDEX access_log_client_ip_ix ON access_log (client_ip)
WHERE NOT (client_ip > inet '192.168.100.0' AND
client_ip < inet '192.168.100.255');
https://www.postgresql.org/docs/current/indexes-types.html
Thursday, 31 January 2019
Wednesday, 30 January 2019
postgres 13
SELECT col1
FROM tab1
WHERE EXISTS (SELECT 1 FROM tab2 WHERE col2 = tab1.col2);
SELECT * FROM generate_series(5,1,-2);
generate_series
-----------------
5
3
1
(3 rows)
SELECT current_date + s.a AS dates FROM generate_series(0,14,7) AS s(a);
dates
------------
2004-02-05
2004-02-12
2004-02-19
(3 rows)
CREATE FUNCTION test_event_trigger_for_drops()
RETURNS event_trigger LANGUAGE plpgsql AS $$
DECLARE
obj record;
BEGIN
FOR obj IN SELECT * FROM pg_event_trigger_dropped_objects()
LOOP
RAISE NOTICE '% dropped object: % %.% %',
tg_tag,
obj.object_type,
obj.schema_name,
obj.object_name,
obj.object_identity;
END LOOP;
END
$$;
CREATE EVENT TRIGGER test_event_trigger_for_drops
ON sql_drop
EXECUTE FUNCTION test_event_trigger_for_drops();
https://www.postgresql.org/docs/current/functions-event-triggers.html
FROM tab1
WHERE EXISTS (SELECT 1 FROM tab2 WHERE col2 = tab1.col2);
SELECT * FROM generate_series(5,1,-2);
generate_series
-----------------
5
3
1
(3 rows)
SELECT current_date + s.a AS dates FROM generate_series(0,14,7) AS s(a);
dates
------------
2004-02-05
2004-02-12
2004-02-19
(3 rows)
CREATE FUNCTION test_event_trigger_for_drops()
RETURNS event_trigger LANGUAGE plpgsql AS $$
DECLARE
obj record;
BEGIN
FOR obj IN SELECT * FROM pg_event_trigger_dropped_objects()
LOOP
RAISE NOTICE '% dropped object: % %.% %',
tg_tag,
obj.object_type,
obj.schema_name,
obj.object_name,
obj.object_identity;
END LOOP;
END
$$;
CREATE EVENT TRIGGER test_event_trigger_for_drops
ON sql_drop
EXECUTE FUNCTION test_event_trigger_for_drops();
https://www.postgresql.org/docs/current/functions-event-triggers.html
Tuesday, 29 January 2019
postgres 12 case array, range operator
SELECT * FROM test;
a
---
1
2
3
SELECT a,
CASE WHEN a=1 THEN 'one'
WHEN a=2 THEN 'two'
ELSE 'other'
END
FROM test;
a | case
---+-------
1 | one
2 | two
3 | other
SELECT ... WHERE CASE WHEN x <> 0 THEN y/x > 1.5 ELSE false END;
a
---
1
2
3
SELECT a,
CASE WHEN a=1 THEN 'one'
WHEN a=2 THEN 'two'
ELSE 'other'
END
FROM test;
a | case
---+-------
1 | one
2 | two
3 | other
SELECT ... WHERE CASE WHEN x <> 0 THEN y/x > 1.5 ELSE false END;
| Operator | Description | Example | Result |
|---|---|---|---|
= | equal | ARRAY[1.1,2.1,3.1]::int[] = ARRAY[1,2,3] | t |
<> | not equal | ARRAY[1,2,3] <> ARRAY[1,2,4] | t |
< | less than | ARRAY[1,2,3] < ARRAY[1,2,4] | t |
> | greater than | ARRAY[1,4,3] > ARRAY[1,2,4] | t |
<= | less than or equal | ARRAY[1,2,3] <= ARRAY[1,2,3] | t |
>= | greater than or equal | ARRAY[1,4,3] >= ARRAY[1,4,3] | t |
@> | contains | ARRAY[1,4,3] @> ARRAY[3,1] | t |
<@ | is contained by | ARRAY[2,7] <@ ARRAY[1,7,4,2,6] | t |
&& | overlap (have elements in common) | ARRAY[1,4,3] && ARRAY[2,1] | t |
|| | array-to-array concatenation | ARRAY[1,2,3] || ARRAY[4,5,6] | {1,2,3,4,5,6} |
|| | array-to-array concatenation | ARRAY[1,2,3] || ARRAY[[4,5,6],[7,8,9]] | {{1,2,3},{4,5,6},{7,8,9}} |
|| | element-to-array concatenation | 3 || ARRAY[4,5,6] | {3,4,5,6} |
|| | array-to-element concatenation | ARRAY[4,5,6] || 7 | {4,5,6,7} |
| Operator | Description | Example | Result |
|---|---|---|---|
= | equal | int4range(1,5) = '[1,4]'::int4range | t |
<> | not equal | numrange(1.1,2.2) <> numrange(1.1,2.3) | t |
< | less than | int4range(1,10) < int4range(2,3) | t |
> | greater than | int4range(1,10) > int4range(1,5) | t |
<= | less than or equal | numrange(1.1,2.2) <= numrange(1.1,2.2) | t |
>= | greater than or equal | numrange(1.1,2.2) >= numrange(1.1,2.0) | t |
@> | contains range | int4range(2,4) @> int4range(2,3) | t |
@> | contains element | '[2011-01-01,2011-03-01)'::tsrange @> '2011-01-10'::timestamp | t |
<@ | range is contained by | int4range(2,4) <@ int4range(1,7) | t |
<@ | element is contained by | 42 <@ int4range(1,7) | f |
&& | overlap (have points in common) | int8range(3,7) && int8range(4,12) | t |
<< | strictly left of | int8range(1,10) << int8range(100,110) | t |
>> | strictly right of | int8range(50,60) >> int8range(20,30) | t |
&< | does not extend to the right of | int8range(1,20) &< int8range(18,20) | t |
&> | does not extend to the left of | int8range(7,20) &> int8range(5,10) | t |
-|- | is adjacent to | numrange(1.1,2.2) -|- numrange(2.2,3.3) | t |
+ | union | numrange(5,15) + numrange(10,20) | [5,20) |
* | intersection | int8range(5,15) * int8range(10,20) | [10,15) |
- | difference | int8range(5,15) - int8range(10,20) | [5,10) |
Monday, 28 January 2019
postgres 11 like, date
LIKE acts like the equals operator. An underscore (_) in pattern stands for (matches) any single character; a percent sign (%) matches any sequence of zero or more characters.
'abc' LIKE 'abc' true
'abc' LIKE 'a%' true
'abc' LIKE '_b_' true
'abc' LIKE 'c' false
SELECT (DATE '2001-02-16', DATE '2001-12-21') OVERLAPS
(DATE '2001-10-30', DATE '2002-10-30');
Result: true
SELECT (DATE '2001-02-16', INTERVAL '100 days') OVERLAPS
(DATE '2001-10-30', DATE '2002-10-30');
Result: false
SELECT (DATE '2001-10-29', DATE '2001-10-30') OVERLAPS
(DATE '2001-10-30', DATE '2001-10-31');
Result: false
SELECT (DATE '2001-10-30', DATE '2001-10-30') OVERLAPS
(DATE '2001-10-30', DATE '2001-10-31');
Result: true
SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40');
Result: 16
select age(current_date, timestamp '1957-06-13');
61years 7mons 15days
https://www.postgresql.org/docs/current/functions-datetime.html
Sunday, 27 January 2019
postgres 10 range
int4range — Range of integer
int8range — Range of bigint
numrange — Range of numeric
tsrange — Range of timestamp without time zone
tstzrange — Range of timestamp with time zone
daterange — Range of date
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
-- Containment
SELECT int4range(10, 20) @> 3;
false
-- Overlaps
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
true
-- Extract the upper bound
SELECT upper(int8range(15, 25));
25
-- Compute the intersection
SELECT int4range(10, 20) * int4range(15, 25);
[15,20)
-- Is the range empty?
SELECT isempty(numrange(1, 5));
false
-- includes 3, does not include 7, and does include all points in between
SELECT '[3,7)'::int4range;
-- does not include either 3 or 7, but includes all points in between
SELECT '(3,7)'::int4range;
-------------------------------------------------
CREATE EXTENSION btree_gist;
CREATE TABLE room_reservation (
room text,
during tsrange,
EXCLUDE USING GIST (room WITH =, during WITH &&)
);
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:00, 2010-01-01 15:00)');
INSERT 0 1
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:30, 2010-01-01 15:30)');
ERROR: conflicting key value violates exclusion constraint "room_reservation_room_during_excl"
DETAIL: Key (room, during)=(123A, ["2010-01-01 14:30:00","2010-01-01 15:30:00")) conflicts
with existing key (room, during)=(123A, ["2010-01-01 14:00:00","2010-01-01 15:00:00")).
INSERT INTO room_reservation VALUES
('123B', '[2010-01-01 14:30, 2010-01-01 15:30)');
INSERT 0 1
int8range — Range of bigint
numrange — Range of numeric
tsrange — Range of timestamp without time zone
tstzrange — Range of timestamp with time zone
daterange — Range of date
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
-- Containment
SELECT int4range(10, 20) @> 3;
false
-- Overlaps
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
true
-- Extract the upper bound
SELECT upper(int8range(15, 25));
25
-- Compute the intersection
SELECT int4range(10, 20) * int4range(15, 25);
[15,20)
-- Is the range empty?
SELECT isempty(numrange(1, 5));
false
-- includes 3, does not include 7, and does include all points in between
SELECT '[3,7)'::int4range;
-- does not include either 3 or 7, but includes all points in between
SELECT '(3,7)'::int4range;
-------------------------------------------------
CREATE EXTENSION btree_gist;
CREATE TABLE room_reservation (
room text,
during tsrange,
EXCLUDE USING GIST (room WITH =, during WITH &&)
);
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:00, 2010-01-01 15:00)');
INSERT 0 1
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:30, 2010-01-01 15:30)');
ERROR: conflicting key value violates exclusion constraint "room_reservation_room_during_excl"
DETAIL: Key (room, during)=(123A, ["2010-01-01 14:30:00","2010-01-01 15:30:00")) conflicts
with existing key (room, during)=(123A, ["2010-01-01 14:00:00","2010-01-01 15:00:00")).
INSERT INTO room_reservation VALUES
('123B', '[2010-01-01 14:30, 2010-01-01 15:30)');
INSERT 0 1
Saturday, 26 January 2019
postgres 9 composite types
CREATE TYPE complex AS (
r double precision,
i double precision
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
CREATE FUNCTION price_extension(inventory_item, integer) RETURNS numeric
AS 'SELECT $1.price * $2' LANGUAGE SQL;
SELECT price_extension(item, 10) FROM on_hand;
since the name item is taken to be a table name, not a column name of on_hand, per SQL syntax rules. You must write it like this:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
or
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
INSERT INTO mytab (complex_col) VALUES((1.1,2.2));
UPDATE mytab SET complex_col = ROW(1.1,2.2) WHERE ...;
UPDATE mytab SET complex_col.r = (complex_col).r + 1 WHERE ...;INSERT INTO mytab (complex_col.r, complex_col.i) VALUES(1.1, 2.2);
SELECT (myfunc(x)).* FROM some_table;
SELECT (myfunc(x)).a, (myfunc(x)).b, (myfunc(x)).c FROM some_table;
r double precision,
i double precision
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
CREATE FUNCTION price_extension(inventory_item, integer) RETURNS numeric
AS 'SELECT $1.price * $2' LANGUAGE SQL;
SELECT price_extension(item, 10) FROM on_hand;
since the name item is taken to be a table name, not a column name of on_hand, per SQL syntax rules. You must write it like this:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
or
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
INSERT INTO mytab (complex_col) VALUES((1.1,2.2));
UPDATE mytab SET complex_col = ROW(1.1,2.2) WHERE ...;
UPDATE mytab SET complex_col.r = (complex_col).r + 1 WHERE ...;INSERT INTO mytab (complex_col.r, complex_col.i) VALUES(1.1, 2.2);
SELECT (myfunc(x)).* FROM some_table;
SELECT (myfunc(x)).a, (myfunc(x)).b, (myfunc(x)).c FROM some_table;
Thursday, 24 January 2019
postgres 8 type, array
CREATE TYPE happiness AS ENUM ('happy', 'very happy', 'ecstatic');
CREATE TABLE holidays (
num_weeks integer,
happiness happiness
);
INSERT INTO holidays(num_weeks,happiness) VALUES (4, 'happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (6, 'very happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (8, 'ecstatic');
INSERT INTO holidays(num_weeks,happiness) VALUES (2, 'sad');
ERROR: invalid input value for enum happiness: "sad"
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood = holidays.happiness;
ERROR: operator does not exist: mood = happiness
-------------------------------------
If you really need to do something like that, you can either write a custom operator or add explicit casts to your query:
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood::text = holidays.happiness::text;
name | num_weeks
------+-----------
Moe | 4
(1 row)
--------------------------------
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
------------------------------------
an array of n elements starts with array[1] and ends with array[n].
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
UPDATE sal_emp SET pay_by_quarter[4] = 15000
WHERE name = 'Bill';
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
SELECT array_prepend(1, ARRAY[2,3]);
array_prepend
---------------
{1,2,3}
(1 row)
SELECT array_append(ARRAY[1,2], 3);
array_append
--------------
{1,2,3}
(1 row)
SELECT array_cat(ARRAY[1,2], ARRAY[3,4]);
array_cat
-----------
{1,2,3,4}
(1 row)
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter);
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
SELECT array_position(ARRAY['sun','mon','tue','wed','thu','fri','sat'], 'mon');
array_positions
-----------------
2
SELECT array_positions(ARRAY[1, 4, 3, 1, 3, 4, 2, 1], 1);
array_positions
-----------------
{1,4,8}
CREATE TABLE holidays (
num_weeks integer,
happiness happiness
);
INSERT INTO holidays(num_weeks,happiness) VALUES (4, 'happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (6, 'very happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (8, 'ecstatic');
INSERT INTO holidays(num_weeks,happiness) VALUES (2, 'sad');
ERROR: invalid input value for enum happiness: "sad"
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood = holidays.happiness;
ERROR: operator does not exist: mood = happiness
-------------------------------------
If you really need to do something like that, you can either write a custom operator or add explicit casts to your query:
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood::text = holidays.happiness::text;
name | num_weeks
------+-----------
Moe | 4
(1 row)
--------------------------------
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
------------------------------------
an array of n elements starts with array[1] and ends with array[n].
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
UPDATE sal_emp SET pay_by_quarter[4] = 15000
WHERE name = 'Bill';
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
SELECT array_prepend(1, ARRAY[2,3]);
array_prepend
---------------
{1,2,3}
(1 row)
SELECT array_append(ARRAY[1,2], 3);
array_append
--------------
{1,2,3}
(1 row)
SELECT array_cat(ARRAY[1,2], ARRAY[3,4]);
array_cat
-----------
{1,2,3,4}
(1 row)
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter);
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
SELECT array_position(ARRAY['sun','mon','tue','wed','thu','fri','sat'], 'mon');
array_positions
-----------------
2
SELECT array_positions(ARRAY[1, 4, 3, 1, 3, 4, 2, 1], 1);
array_positions
-----------------
{1,4,8}
Tuesday, 22 January 2019
postgres 7 with recursive
using recursive query to find all sub levels given top level for tree architecture.


with recursive tree_map(sub_level, current_level, quantity) as(
with tree as (
select * from (
values(array['B','C'], 'A' , 1),
(array['BA', 'BB'], 'B', 3),
(array['CA','CB','CC'], 'C', 2),
(array['BAA','BAB','BAC'], 'BA', 4),
(array['BBA','BBB'], 'BB', 2),
(array['CAA','CAB'], 'CA', 2),
(array['CBA'], 'CB', 5),
(array['CCA','CCB','CCC','CCD','CCE'], 'CC', 1),
(array['x'], 'BAA', 10),
(array['y'], 'BAB', 6),
(array['z'], 'BAC', 8),
(array['y'], 'BBA', 3),
(array['x'], 'BBB', 5),
(array['x'], 'CAA', 2),
(array['y'], 'CAB', 10),
(array['x'], 'CBA', 1),
(array['y'], 'CCA', 7),
(array['z'], 'CCB', 11)
)
as t(sub_level, current_level, quantity)
)
select sub_level, current_level, quantity from tree where current_level='A'
union all
select tree.sub_level, tree.current_level, tree.quantity
from tree , tree_map
where tree_map.sub_level @> array[tree.current_level] --contains
)
select sub_level, sum(quantity) as total_quantity from tree_map
where sub_level @> array['x'] or sub_level @> array['y'] or sub_level @> array['z']
group by sub_level
--------------------------------------
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
----------------------------------
WITH RECURSIVE t(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM t WHERE n < 100
)
SELECT sum(n) FROM t;
-----------------------------------
WITH moved_rows AS (
DELETE FROM products
WHERE
"date" >= '2010-10-01' AND
"date" < '2010-11-01'
RETURNING *
)
INSERT INTO products_log
SELECT * FROM moved_rows;
----------------------------------
https://www.postgresql.org/docs/current/queries-with.html
A
B C
BA BB CA CB CC
...........

tree view

find total base elements of the tree
with tree as (
select * from (
values(array['B','C'], 'A' , 1),
(array['BA', 'BB'], 'B', 3),
(array['CA','CB','CC'], 'C', 2),
(array['BAA','BAB','BAC'], 'BA', 4),
(array['BBA','BBB'], 'BB', 2),
(array['CAA','CAB'], 'CA', 2),
(array['CBA'], 'CB', 5),
(array['CCA','CCB','CCC','CCD','CCE'], 'CC', 1),
(array['x'], 'BAA', 10),
(array['y'], 'BAB', 6),
(array['z'], 'BAC', 8),
(array['y'], 'BBA', 3),
(array['x'], 'BBB', 5),
(array['x'], 'CAA', 2),
(array['y'], 'CAB', 10),
(array['x'], 'CBA', 1),
(array['y'], 'CCA', 7),
(array['z'], 'CCB', 11)
)
as t(sub_level, current_level, quantity)
)
select sub_level, current_level, quantity from tree where current_level='A'
union all
select tree.sub_level, tree.current_level, tree.quantity
from tree , tree_map
where tree_map.sub_level @> array[tree.current_level] --contains
)
select sub_level, sum(quantity) as total_quantity from tree_map
where sub_level @> array['x'] or sub_level @> array['y'] or sub_level @> array['z']
group by sub_level
--------------------------------------
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
----------------------------------
WITH RECURSIVE t(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM t WHERE n < 100
)
SELECT sum(n) FROM t;
-----------------------------------
WITH moved_rows AS (
DELETE FROM products
WHERE
"date" >= '2010-10-01' AND
"date" < '2010-11-01'
RETURNING *
)
INSERT INTO products_log
SELECT * FROM moved_rows;
----------------------------------
https://www.postgresql.org/docs/current/queries-with.html
Monday, 21 January 2019
How to Install and configuration PostgreSQL on Ubuntu Linux
--open terminal
CTRL + ALT + T
--access root
sudo su -
--install postgres
apt-get install postgresql postgresql-contrib
--configure postgres to start upon server boot
update-rc.d postgresql enable
--install pgadmin
sudo apt-get install pgadmin4
--start postgres
service postgresql start
--set password
sudo su -
psql
alter user postgres with password 'xxx'
--open pgadmin
--right click servers -> create -> server
--gereral -> name: localhost
--connection -> address: 127.0.0.1 -> password: xxx
--save
reference:
https://www.youtube.com/watch?v=-LwI4HMR_Eg
https://www.godaddy.com/garage/how-to-install-postgresql-on-ubuntu-14-04/
https://www.liquidweb.com/kb/what-is-the-default-password-for-postgresql/
http://www.indjango.com/ubuntu-install-postgresql-and-pgadmin/
https://milq.github.io/useful-terminal-commands-ubuntu-debian/
Ctrl + Alt + H - show hidden files
https://www.howtogeek.com/howto/ubuntu/view-hidden-files-and-folders-in-ubuntu-file-browser/
CTRL + ALT + T
--access root
sudo su -
--install postgres
apt-get install postgresql postgresql-contrib
--configure postgres to start upon server boot
update-rc.d postgresql enable
--install pgadmin
sudo apt-get install pgadmin4
--start postgres
service postgresql start
--set password
sudo su -
psql
alter user postgres with password 'xxx'
--open pgadmin
--right click servers -> create -> server
--gereral -> name: localhost
--connection -> address: 127.0.0.1 -> password: xxx
--save
reference:
https://www.youtube.com/watch?v=-LwI4HMR_Eg
https://www.godaddy.com/garage/how-to-install-postgresql-on-ubuntu-14-04/
https://www.liquidweb.com/kb/what-is-the-default-password-for-postgresql/
http://www.indjango.com/ubuntu-install-postgresql-and-pgadmin/
https://milq.github.io/useful-terminal-commands-ubuntu-debian/
Ctrl + Alt + H - show hidden files
https://www.howtogeek.com/howto/ubuntu/view-hidden-files-and-folders-in-ubuntu-file-browser/
Sunday, 20 January 2019
postgres 6 returning, lateral, group by
INSERT INTO products (product_no, name, price)
SELECT product_no, name, price FROM new_products
WHERE release_date = 'today';
CREATE TABLE users (firstname text, lastname text, id serial primary key);
INSERT INTO users (firstname, lastname) VALUES ('Joe', 'Cool') RETURNING id;
In a DELETE, the data available to RETURNING is the content of the deleted row.
DELETE FROM products
WHERE obsoletion_date = 'today'
RETURNING *;
LATERAL allows them to reference columns provided by preceding FROM items
SELECT m.name
FROM manufacturers m LEFT JOIN LATERAL get_product_names(m.id) pname ON true
WHERE pname IS NULL;
SELECT product_id, p.name, (sum(s.units) * p.price) AS sales
FROM products p LEFT JOIN sales s USING (product_id)
GROUP BY product_id, p.name, p.price;
SELECT product_id, p.name, (sum(s.units) * (p.price - p.cost)) AS profit
FROM products p LEFT JOIN sales s USING (product_id)
WHERE s.date > CURRENT_DATE - INTERVAL '4 weeks'
GROUP BY product_id, p.name, p.price, p.cost
HAVING sum(p.price * s.units) > 5000;
=> SELECT * FROM items_sold;
brand | size | sales
-------+------+-------
Foo | L | 10
Foo | M | 20
Bar | M | 15
Bar | L | 5
(4 rows)
=> SELECT brand, size, sum(sales) FROM items_sold GROUP BY GROUPING SETS ((brand), (size), ());
brand | size | sum
-------+------+-----
Foo | | 30
Bar | | 20
| L | 15
| M | 35
| | 50
(5 rows)
ROLLUP ( e1, e2, e3, ... ) is equivalent to
GROUPING SETS (
( e1, e2, e3, ... ),
...
( e1, e2 ),
( e1 ),
( )
)
CUBE ( a, b, c ) is equivalent to
GROUPING SETS (
( a, b, c ),
( a, b ),
( a, c ),
( a ),
( b, c ),
( b ),
( c ),
( )
)
SELECT product_no, name, price FROM new_products
WHERE release_date = 'today';
CREATE TABLE users (firstname text, lastname text, id serial primary key);
INSERT INTO users (firstname, lastname) VALUES ('Joe', 'Cool') RETURNING id;
In a DELETE, the data available to RETURNING is the content of the deleted row.
DELETE FROM products
WHERE obsoletion_date = 'today'
RETURNING *;
LATERAL allows them to reference columns provided by preceding FROM items
SELECT m.name
FROM manufacturers m LEFT JOIN LATERAL get_product_names(m.id) pname ON true
WHERE pname IS NULL;
SELECT product_id, p.name, (sum(s.units) * p.price) AS sales
FROM products p LEFT JOIN sales s USING (product_id)
GROUP BY product_id, p.name, p.price;
SELECT product_id, p.name, (sum(s.units) * (p.price - p.cost)) AS profit
FROM products p LEFT JOIN sales s USING (product_id)
WHERE s.date > CURRENT_DATE - INTERVAL '4 weeks'
GROUP BY product_id, p.name, p.price, p.cost
HAVING sum(p.price * s.units) > 5000;
=> SELECT * FROM items_sold;
brand | size | sales
-------+------+-------
Foo | L | 10
Foo | M | 20
Bar | M | 15
Bar | L | 5
(4 rows)
=> SELECT brand, size, sum(sales) FROM items_sold GROUP BY GROUPING SETS ((brand), (size), ());
brand | size | sum
-------+------+-----
Foo | | 30
Bar | | 20
| L | 15
| M | 35
| | 50
(5 rows)
ROLLUP ( e1, e2, e3, ... ) is equivalent to
GROUPING SETS (
( e1, e2, e3, ... ),
...
( e1, e2 ),
( e1 ),
( )
)
CUBE ( a, b, c ) is equivalent to
GROUPING SETS (
( a, b, c ),
( a, b ),
( a, c ),
( a ),
( b, c ),
( b ),
( c ),
( )
)
Saturday, 19 January 2019
postgres 5 inheritance
CREATE TABLE cities (
name text,
population float,
altitude int -- in feet
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
insert into cities(name, altitude) values
('Las Vegas', 2174),('Mariposa', 1953);
insert into capitals(name, altitude) values
('Madison', 845);
select * from cities;

select * from only cities;

SELECT c.tableoid::regclass, c.name, c.altitude FROM cities c

ALTER TABLE will propagate any changes in column data definitions and check constraints down the inheritance hierarchy.
dropping columns that are depended on by other tables is only possible when using the CASCADE option.
if we were to specify that cities.name REFERENCES some other table, this constraint would not automatically propagate to capitals. In this case you could work around it by manually adding the same REFERENCES constraint to capitals.
Specifying that another table's column REFERENCES cities(name) would allow the other table to contain city names, but not capital names
name text,
population float,
altitude int -- in feet
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
insert into cities(name, altitude) values
('Las Vegas', 2174),('Mariposa', 1953);
insert into capitals(name, altitude) values
('Madison', 845);
select * from cities;


SELECT c.tableoid::regclass, c.name, c.altitude FROM cities c

ALTER TABLE will propagate any changes in column data definitions and check constraints down the inheritance hierarchy.
dropping columns that are depended on by other tables is only possible when using the CASCADE option.
if we were to specify that cities.name REFERENCES some other table, this constraint would not automatically propagate to capitals. In this case you could work around it by manually adding the same REFERENCES constraint to capitals.
Specifying that another table's column REFERENCES cities(name) would allow the other table to contain city names, but not capital names
Friday, 18 January 2019
postgres 4 Row Security Policies

mallory has medium privilege

she can't view very secret information
set role alice;
UPDATE users SET group_id = 1 WHERE user_name = 'mallory';

mallory's privilege is dropped to low by alice

she can only view barely secret info now
--add different database users
create role alice;
create role bob;
create role mallory;
-- definition of privilege groups
CREATE TABLE groups (group_id int PRIMARY KEY,
group_name text NOT NULL);
INSERT INTO groups VALUES
(1, 'low'),
(2, 'medium'),
(5, 'high');
GRANT ALL ON groups TO alice; -- alice is the administrator
GRANT SELECT ON groups TO public;
-- definition of users' privilege levels
CREATE TABLE users (user_name text PRIMARY KEY,
group_id int NOT NULL REFERENCES groups);
INSERT INTO users VALUES
('alice', 5),
('bob', 2),
('mallory', 2);
--giver permission
GRANT ALL ON users TO alice;
GRANT SELECT ON users TO public;
-- table holding the information to be protected
CREATE TABLE information (info text,
group_id int NOT NULL REFERENCES groups);
INSERT INTO information VALUES
('barely secret', 1),
('slightly secret', 2),
('very secret', 5);
--protect information from being viewed or updated by users without enough privilege
ALTER TABLE information ENABLE ROW LEVEL SECURITY;
-- a row should be visible to/updatable by users whose security group_id is
-- greater than or equal to the row's group_id
--set restriction
CREATE POLICY fp_s ON information FOR SELECT
USING (group_id <= (SELECT group_id FROM users WHERE user_name = current_user));
CREATE POLICY fp_u ON information FOR UPDATE
USING (group_id <= (SELECT group_id FROM users WHERE user_name = current_user));
-- we rely only on RLS to protect the information table
GRANT ALL ON information TO public
-------------------------------
Now suppose that alice wishes to change the “slightly secret” information, but decides that mallory should not be trusted with the new content of that row, so she does:
BEGIN;
UPDATE users SET group_id = 1 WHERE user_name = 'mallory';
COMMIT;
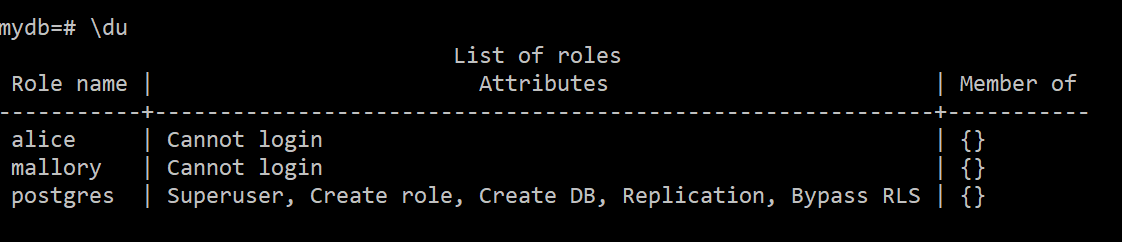

postgres 3
CREATE TABLE products (
product_no integer,
name text,
price numeric DEFAULT 9.99
);
CREATE TABLE products (
product_no integer PRIMARY KEY ,
name text UNIQUE,
price numeric CHECK (price > 0),
discounted_price numeric NOT NULL,
CHECK (discounted_price > 0 AND price > discounted_price)
);
CREATE TABLE t1 (
a integer PRIMARY KEY,
b integer,
c integer,
FOREIGN KEY (b, c) REFERENCES other_table (c1, c2)
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text,
...
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT, --SET NULL and SET DEFAULT
order_id integer REFERENCES orders ON DELETE CASCADE,
quantity integer,
PRIMARY KEY (product_no, order_id)
);
ALTER TABLE products ADD COLUMN description text;
ALTER TABLE products DROP COLUMN description CASCADE;
ALTER TABLE products ADD CHECK (name <> '');
ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no);
ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups;
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;
ALTER TABLE products DROP CONSTRAINT some_name;
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
ALTER TABLE products RENAME COLUMN product_no TO product_number;
ALTER TABLE products RENAME TO items;
product_no integer,
name text,
price numeric DEFAULT 9.99
);
CREATE TABLE products (
product_no integer PRIMARY KEY ,
name text UNIQUE,
price numeric CHECK (price > 0),
discounted_price numeric NOT NULL,
CHECK (discounted_price > 0 AND price > discounted_price)
);
CREATE TABLE t1 (
a integer PRIMARY KEY,
b integer,
c integer,
FOREIGN KEY (b, c) REFERENCES other_table (c1, c2)
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text,
...
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT, --SET NULL and SET DEFAULT
order_id integer REFERENCES orders ON DELETE CASCADE,
quantity integer,
PRIMARY KEY (product_no, order_id)
);
ALTER TABLE products ADD COLUMN description text;
ALTER TABLE products DROP COLUMN description CASCADE;
ALTER TABLE products ADD CHECK (name <> '');
ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no);
ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups;
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;
ALTER TABLE products DROP CONSTRAINT some_name;
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
ALTER TABLE products RENAME COLUMN product_no TO product_number;
ALTER TABLE products RENAME TO items;
Thursday, 17 January 2019
postgres 2
CREATE VIEW myview AS
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
CREATE TABLE cities (
name text,
population real,
altitude int -- (in ft)
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
CREATE FUNCTION concat_lower_or_upper(a text, b text, uppercase boolean DEFAULT false)
RETURNS text
AS
$$
SELECT CASE
WHEN $3 THEN UPPER($1 || ' ' || $2)
ELSE LOWER($1 || ' ' || $2)
END;
$$
LANGUAGE SQL IMMUTABLE STRICT;
SELECT concat_lower_or_upper('Hello', 'World', true);
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
CREATE TABLE cities (
name text,
population real,
altitude int -- (in ft)
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
CREATE FUNCTION concat_lower_or_upper(a text, b text, uppercase boolean DEFAULT false)
RETURNS text
AS
$$
SELECT CASE
WHEN $3 THEN UPPER($1 || ' ' || $2)
ELSE LOWER($1 || ' ' || $2)
END;
$$
LANGUAGE SQL IMMUTABLE STRICT;
SELECT concat_lower_or_upper('Hello', 'World', true);
Wednesday, 16 January 2019
postgres 1
insert into weather values ('San Francisco', 46, 50, 0.25, '1994-11-27')
insert into cities values('San Francisco', '(-194.0, 53.0)')
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
insert into weather (date, city, temp_hi, temp_lo) values ('1994-11-29', 'Hayward', 54, 37)
select * from weather
SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
SELECT * FROM weather
WHERE city = 'San Francisco' AND prcp > 0.0;
SELECT * FROM weather
ORDER BY city;
SELECT * FROM weather
ORDER BY city, temp_lo;
SELECT DISTINCT city
FROM weather;
SELECT DISTINCT city
FROM weather
ORDER BY city;
SELECT *
FROM weather, cities
WHERE city = name;
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather, cities
WHERE cities.name = weather.city;
SELECT *
FROM weather INNER JOIN cities ON (weather.city = cities.name);
SELECT *
FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name);
SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
W2.city, W2.temp_lo AS low, W2.temp_hi AS high
FROM weather W1, weather W2
WHERE W1.temp_lo < W2.temp_lo
AND W1.temp_hi > W2.temp_hi;
SELECT *
FROM weather w, cities c
WHERE w.city = c.name;
SELECT max(temp_lo) FROM weather;
SELECT city FROM weather
WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
SELECT city, max(temp_lo)
FROM weather
GROUP BY city;
SELECT city, max(temp_lo)
FROM weather
GROUP BY city
HAVING max(temp_lo) < 40;
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%' -- (1)
GROUP BY city
HAVING max(temp_lo) < 40;
UPDATE weather
SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
WHERE date > '1994-11-28';
SELECT * FROM weather;
DELETE FROM weather WHERE city = 'San Francissco';
insert into cities values('San Francisco', '(-194.0, 53.0)')
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
insert into weather (date, city, temp_hi, temp_lo) values ('1994-11-29', 'Hayward', 54, 37)
select * from weather
SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
SELECT * FROM weather
WHERE city = 'San Francisco' AND prcp > 0.0;
SELECT * FROM weather
ORDER BY city;
SELECT * FROM weather
ORDER BY city, temp_lo;
SELECT DISTINCT city
FROM weather;
SELECT DISTINCT city
FROM weather
ORDER BY city;
SELECT *
FROM weather, cities
WHERE city = name;
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather, cities
WHERE cities.name = weather.city;
SELECT *
FROM weather INNER JOIN cities ON (weather.city = cities.name);
SELECT *
FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name);
SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
W2.city, W2.temp_lo AS low, W2.temp_hi AS high
FROM weather W1, weather W2
WHERE W1.temp_lo < W2.temp_lo
AND W1.temp_hi > W2.temp_hi;
SELECT *
FROM weather w, cities c
WHERE w.city = c.name;
SELECT max(temp_lo) FROM weather;
SELECT city FROM weather
WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
SELECT city, max(temp_lo)
FROM weather
GROUP BY city;
SELECT city, max(temp_lo)
FROM weather
GROUP BY city
HAVING max(temp_lo) < 40;
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%' -- (1)
GROUP BY city
HAVING max(temp_lo) < 40;
UPDATE weather
SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
WHERE date > '1994-11-28';
SELECT * FROM weather;
DELETE FROM weather WHERE city = 'San Francissco';
Sunday, 13 January 2019
node upload & download with gridfs
project site: https://chuanshuoge1-gridfs.herokuapp.com/
In MongoDB, use GridFS for storing files larger than 16 MB.
GridFS divides the document into chunks of size chunkSize 255 kilobytes (kB).

support all file format

extract download zip file
 2 collections created, meta data and binary chunks
2 collections created, meta data and binary chunks

metadata
[ { _id: 5c3bf5a015291c001743024b,
length: 574974,
chunkSize: 261120,
uploadDate: 2019-01-14T02:36:18.472Z,
filename: '521476_013.gif',
md5: '55d75f257bd0354ca843763306f6c90d',
contentType: 'image/gif' },
...
chunkSize: 261120,
uploadDate: 2019-01-14T02:37:04.404Z,
filename: 'IMG_20170517_215456.3gp',
md5: '74c29e75141e225894f109a2fc0de00c',
contentType: 'video/3gpp' } ]
--------------------------------------------------
binary chunks
{
"_id": {
"$oid": "5c3bf5a315291c0017430255"
},
"files_id": {
"$oid": "5c3bf5a015291c001743024d"
},
"n": 1,
"data": "<Binary Data>"
}
{
"_id": {
"$oid": "5c3bf5a315291c0017430256"
},
"files_id": {
"$oid": "5c3bf5a015291c001743024d"
},
"n": 2,
"data": "<Binary Data>"
}
------------------------------------------
chunks assembled into binary file
IMG_20170517_215456.3gp
<Buffer ff d8 ff e1 30 7d 45 78 69 66 00 00 49 49 2a 00 08 00 00 00 11 00 0e 01 02 00 20 00 00 00 da 00 00 00 0f 01 02 00 20 00 00 00 fa 00 00 00 10 01 02 00 ... >

package.json
{
"name": "upload",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"start": "node server.js",
"dev": "nodemon server.js",
"heroku-postbuild": "cd client && npm install && npm run build"
},
"author": "",
"license": "ISC",
"dependencies": {
"body-parser": "^1.18.3",
"express": "^4.16.4",
"gridfs-stream": "^1.1.1",
"jszip": "^3.1.5",
"mongoose": "^5.4.2",
"multer": "^1.4.1",
"multer-gridfs-storage": "^3.2.3"
}
}
------------------------------------------
server.js
const express = require('express')
const bodyParser = require('body-parser')
const multer = require('multer');
const path = require('path');
const mongoose = require('mongoose');
const jszip = require('jszip');
const gridStorage = require('multer-gridfs-storage');
const gridStream = require('gridfs-stream');
//fix finOne bug
eval(`gridStream.prototype.findOne = ${gridStream.prototype.findOne.toString().replace('nextObject', 'next')}`);
const app = express();
//Body parser Middleware
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
//public folder
//app.use(express.static('./public'));
app.use(express.static(path.join(__dirname, 'client/build')));
const mongoURL = "mongodb://xxxxxxx@ds149984.mlab.com:49984/upload";
//gridfs multer
const storage = new gridStorage({
url: mongoURL,
file: (req, file) => {
const fileInfo = {
filename: file.originalname,
bucketName: 'gridfs'
}
return fileInfo
}
})
const gridUpload = multer({ storage });
//gridfs upload
app.post('/gridUpload', gridUpload.any(), (req, res, next) => {
console.log(req.files)
res.send('ok')
})
//gridfs search
app.get('/gridSearch', (req, res, next) => {
try {
//only download id and name, ignore actual file
gfs.files.find().toArray((err, files) => {
console.log(files)
res.send(files)
})
} catch (err) {
return next(err)
}
})
//gridfs download
app.post('/gridDownload', async (req, res, next) => {
try {
const lists = req.body;
const zip = new jszip();
let downloaded = 0;
lists.map(async (item, index) => {
let fileName;
//find name by id from metadata
await gfs.findOne({ _id: item }, (err, search) => {
if (err) {
console.log(err)
}
console.log(search.filename)
fileName = search.filename;
})
const readStream = gfs.createReadStream({ _id: item });
let fileChunks = [];
//store all chunks into an array
readStream.on('data', chunk => { fileChunks.push(chunk) });
//when all chunks of a files have been read...
readStream.on('end', async () => {
//assemble all chunks into a file
const file = Buffer.concat(fileChunks);
console.log(file);
//store file in zip folder
await zip.file(fileName, file, { base64: true })
console.log(index)
//record # of files donwloaded
downloaded++;
//when all downloaded files are in zip folder...
if (downloaded === lists.length) {
zip.generateAsync({ type: "nodebuffer" })
.then(function (content) {
//deliver zip folder to font end
res.send(content);
})
.catch(err => {
next(err)
});
}
})
})
} catch (err) {
return next(err)
}
})
//gridfs delete
app.delete('/gridDelete', (req, res, next) => {
try {
const lists = req.body;
let deleted = 0;
lists.map((item, index) => {
gfs.remove({ _id: item, root: 'gridfs' }, (err, gridStore) => {
if (err) { return next(err) }
deleted++;
if (deleted === lists.length) {
res.send('deleted')
}
})
})
} catch (err) {
return next(err);
}
});
app.get('*', (req, res) => {
res.sendFile(path.join(__dirname + '/client/build/index.html'));
});
const port = process.env.PORT || 5000;
app.listen(port, () => {
mongoose.connect(mongoURL, {
useNewUrlParser: true
});
});
const db = mongoose.connection;
let gfs;
db.on('error', (err) => console.log(err));
db.once('open', () => {
gfs = gridStream(db.db, mongoose.mongo);
gfs.collection('gridfs');
console.log('server started');
});
---------------------------------------------------
import './App.css';
import 'antd/dist/antd.css';
import { Upload, Icon, message } from 'antd';
const Dragger = Upload.Dragger;
class DragUpload extends Component {
constructor(props) {
super(props);
this.state = {
};
}
onChange(info) {
const status = info.file.status;
if (status !== 'uploading') {
console.log(info.file, info.fileList);
}
if (status === 'done') {
message.success(`${info.file.name} file uploaded successfully.`);
this.props.refresh();
} else if (status === 'error') {
message.error(`${info.file.name} file upload failed.`);
}
}
render() {
const baseUrl = 'https://chuanshuoge1-gridfs.herokuapp.com' || 'http://localhost:3000';
const url = baseUrl + '/gridUpload'
return (
<div style={{ paddingRight: '16px' }}>
<Dragger multiple={true} action={url} onChange={(e) => this.onChange(e)}>
<p className="ant-upload-drag-icon">
<Icon type="inbox" />
</p>
<p className="ant-upload-text">Click or drag file to this area to upload</p>
<p className="ant-upload-hint">Support for a single or bulk upload. Strictly prohibit from uploading company data or other band files</p>
</Dragger>
</div>
);
}
}
export default DragUpload;
import './App.css';
import 'antd/dist/antd.css';
import { Button, message, Progress } from 'antd';
import axios from 'axios';
import saveAs from 'file-saver';
class Download extends Component {
constructor(props) {
super(props);
this.state = {
progress: 0,
};
}
downloadAxios = () => {
this.setState({ progress: 0 })
axios({
url: '/gridDownload',
method: 'post',
data: this.props.check,
responseType: 'blob', // important
onDownloadProgress: progressEvent => {
const p = parseInt(progressEvent.loaded / progressEvent.total * 100);
this.setState({ progress: p });
},
})
.then(res => {
console.log(res.data)
const name = Date.now() + '.zip'
saveAs(res.data, name);
})
.catch(err => {
message.error(err)
})
}
render() {
return (
<div >
<Button type='dashed' onClick={() => { this.downloadAxios() }} disabled={this.props.check.length === 0 ? true : false}>Download zip</Button>{' '}
<Progress type="circle" percent={this.state.progress} width={38} />
</div>
);
}
}
export default Download;
client/app.js
import React, { Component } from 'react';
import './App.css';
import ButtonUpload from './buttonUpload';
import Delete from './delete';
import Download from './download';
import { Row, Col, Checkbox, Icon } from 'antd';
import 'antd/dist/antd.css';
import axios from 'axios';
import DragUpload from './dragUpload';
class App extends Component {
constructor(props) {
super(props);
this.state = {
files: [],
downloadCheck: [],
deleteCheck: [],
};
}
componentWillMount() {
this.cloudSearch();
}
cloudSearch() {
axios({
method: 'get',
url: '/gridSearch'
})
.then(res => {
this.setState({ files: res.data })
})
.catch(err => {
console.log(err)
})
}
downloadCheck(e) {
this.setState({ downloadCheck: e })
}
deleteCheck(e) {
this.setState({ deleteCheck: e })
}
render() {
return (
<div style={{ padding: '16px' }}>
<h1 style={{ textAlign: 'center' }}><Icon type="laptop" /> <Icon type="swap" /> <Icon type="global" /> <Icon type="swap" /> <Icon type="database" /> <Icon type="swap" /> <Icon type="global" /> <Icon type="swap" /> <Icon type="cloud" /></h1>
<Row>
<Col xs={12} sm={8}>
<ButtonUpload refresh={() => this.cloudSearch()}></ButtonUpload><br />
<DragUpload refresh={() => this.cloudSearch()}></DragUpload>
</Col>
<Col xs={12} sm={8}>
<h3>Download Files from Cloud</h3>
<Checkbox.Group onChange={(e) => this.downloadCheck(e)} style={{ width: '100%' }} >
<Row>
{this.state.files.map((item, index) =>
<Col key={index}>
<Checkbox value={item._id} >{item.filename}</Checkbox>
</Col>
)}
</Row>
</Checkbox.Group><br /><br />
<Download check={this.state.downloadCheck}></Download><br />
</Col>
<Col xs={12} sm={8}>
<h3>Delete Files on Cloud</h3>
<Checkbox.Group onChange={(e) => this.deleteCheck(e)} style={{ width: '100%' }} >
<Row>
{this.state.files.map((item, index) =>
<Col key={index}>
<Checkbox value={item._id} >{item.filename}</Checkbox>
</Col>
)}
</Row>
</Checkbox.Group><br /><br />
<Delete refresh={() => this.cloudSearch()} check={this.state.deleteCheck}></Delete>
</Col>
</Row>
</div>
);
}
}
export default App;
--------------------------------
client/buttonUpload.js
import React, { Component } from 'react';
import './App.css';
import 'antd/dist/antd.css';
import { Button, Upload, Icon, message, Progress } from 'antd';
import axios from 'axios';
class ButtonUpload extends Component {
constructor(props) {
super(props);
this.state = {
fileList: [],
uploading: false,
progress: 0,
};
}
handleUpload = () => {
const { fileList } = this.state;
const formData = new FormData();
fileList.forEach((file) => {
formData.append('files[]', file);
});
this.setState({
uploading: true,
});
axios({
method: 'post',
url: '/gridUpload',
data: formData,
headers: { 'Content-Type': 'multipart/form-data', "Access-Control-Allow-Origin": "*" },
onUploadProgress: progressEvent => {
const p = parseInt(progressEvent.loaded / progressEvent.total * 99);
this.setState({ progress: p });
},
})
.then(res => {
console.log(res.data);
if (res.data === 'ok') {
this.setState({
fileList: [],
uploading: false,
progress: 100,
});
message.success('upload successful');
this.props.refresh();
}
})
.catch((err) => {
message.error(err.toString());
})
}
render() {
const { uploading, fileList } = this.state;
const configs = {
multiple: true,
onRemove: (file) => {
this.setState((state) => {
const index = state.fileList.indexOf(file);
const newFileList = state.fileList.slice();
newFileList.splice(index, 1);
return {
fileList: newFileList,
};
});
},
beforeUpload: (file) => {
this.setState(state => ({
fileList: [...state.fileList, file],
progress: 0,
}));
return false;
},
fileList,
};
return (
<div >
<Upload {...configs}>
<Button>
<Icon type="upload" /> Select File
</Button>
</Upload>
<Button
type="primary"
onClick={this.handleUpload}
disabled={fileList.length === 0}
loading={uploading}
style={{ marginTop: 16 }}
>
{uploading ? 'Uploading' : 'Start Upload'}
</Button>{' '}
<Progress type="circle" percent={this.state.progress} width={38} />
</div>
);
}
}
export default ButtonUpload;
----------------------------------------------
client/dragUpload.js
import React, { Component } from 'react';import './App.css';
import 'antd/dist/antd.css';
import { Upload, Icon, message } from 'antd';
const Dragger = Upload.Dragger;
class DragUpload extends Component {
constructor(props) {
super(props);
this.state = {
};
}
onChange(info) {
const status = info.file.status;
if (status !== 'uploading') {
console.log(info.file, info.fileList);
}
if (status === 'done') {
message.success(`${info.file.name} file uploaded successfully.`);
this.props.refresh();
} else if (status === 'error') {
message.error(`${info.file.name} file upload failed.`);
}
}
render() {
const baseUrl = 'https://chuanshuoge1-gridfs.herokuapp.com' || 'http://localhost:3000';
const url = baseUrl + '/gridUpload'
return (
<div style={{ paddingRight: '16px' }}>
<Dragger multiple={true} action={url} onChange={(e) => this.onChange(e)}>
<p className="ant-upload-drag-icon">
<Icon type="inbox" />
</p>
<p className="ant-upload-text">Click or drag file to this area to upload</p>
<p className="ant-upload-hint">Support for a single or bulk upload. Strictly prohibit from uploading company data or other band files</p>
</Dragger>
</div>
);
}
}
export default DragUpload;
---------------------------------------
client/download.js
import React, { Component } from 'react';import './App.css';
import 'antd/dist/antd.css';
import { Button, message, Progress } from 'antd';
import axios from 'axios';
import saveAs from 'file-saver';
class Download extends Component {
constructor(props) {
super(props);
this.state = {
progress: 0,
};
}
downloadAxios = () => {
this.setState({ progress: 0 })
axios({
url: '/gridDownload',
method: 'post',
data: this.props.check,
responseType: 'blob', // important
onDownloadProgress: progressEvent => {
const p = parseInt(progressEvent.loaded / progressEvent.total * 100);
this.setState({ progress: p });
},
})
.then(res => {
console.log(res.data)
const name = Date.now() + '.zip'
saveAs(res.data, name);
})
.catch(err => {
message.error(err)
})
}
render() {
return (
<div >
<Button type='dashed' onClick={() => { this.downloadAxios() }} disabled={this.props.check.length === 0 ? true : false}>Download zip</Button>{' '}
<Progress type="circle" percent={this.state.progress} width={38} />
</div>
);
}
}
export default Download;
-------------------------------------
client/delete.js
import React, { Component } from 'react';
import './App.css';
import 'antd/dist/antd.css';
import { Button, message } from 'antd';
import axios from 'axios';
class Delete extends Component {
constructor(props) {
super(props);
this.state = {
};
}
delete = () => {
axios({
method: 'delete',
url: '/gridDelete',
data: this.props.check,
})
.then(res => {
message.success('deleted all')
this.props.refresh();
})
.catch(err => {
console.log(err)
})
}
render() {
return (
<div >
<Button type='danger' onClick={() => { this.delete() }} disabled={this.props.check.length === 0 ? true : false}>Delete</Button>
</div>
);
}
}
export default Delete;
-----------------------------------------
reference:
Subscribe to:
Comments (Atom)